【Redis学习笔记】
官网:Redis
go-redis:redis package - github.com/go-redis/redis/v8 - Go Packages
1. Linux 安装及使用
安装:
1
2
3
4
5# 安装
sudo apt-get install redis
# 使用
redis-cli ping
redis启动redis,测试是否联通:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 指定配置文件启动redis-server
root@hecs-264482:~# redis-server /etc/redis/redis.conf
% 指定端口号启动redis-cli
root@hecs-264482:~# redis-cli -p 6379
# 查看是否联通
127.0.0.1:6379> ping
PONG
# 查看所有的key
127.0.0.1:6379> keys *
1. "username"
2. "mylist"查看服务是否已经启动:
ps -ef|grep redis
 xo_gallery/main/gallery/20230302181609.png)
xo_gallery/main/gallery/20230302181609.png)关闭redis:
1
127.0.0.1:6379> shutdown
 xo_gallery/main/gallery/20230302181609.png)
xo_gallery/main/gallery/20230302181609.png)2. Redis 基本知识
1 | # 切换数据库(Redis共有16个数据库) |
Redis 是单线程的!
Redis 是基于内存操作,CPU不是Redis的性能瓶颈
Redis是单线程的为什么还会这么快?
核心:Redis 是将所有数据全部存入内存中的,所以说用单线程去操作就是最快的!
(因为在多线程中,CPU需要频繁的上下文切换,切换操作同样需要一定的时间,对于内存系统,没有上下文切换时效率就是最高的!)
五大基本数据类型
1. String
1 | ################################################## |
2. List
1 | ################################################## |
1 | **实际上是一个链表** |
3. Set
1 | ################################################## |
4. Hash
1 | ################################################## |
1 | Hash更适合于对象的存储! |
5. Zset
在 set 的基础上增加了一个值,变成一个有序集合
1 | # 添加值 |
三种特殊类型
1. Geospatial
1 | # 只有六个命令 |
1 | collapse: open |
2. Hyperloglog
概念引入:基数(不重复的元素)f
Hyperloglog 可以用来统计基数
可以用来统计网站的访问人数(UV),可以过滤同一用户的多次访问
1 | # 添加元素 |
1 | Hyperloglog 类似于特化的 Set,能够保存大量元素并统计去重后得元素个数 |
3. Bitmap
位存储,类似于用 0/1 来当作 bool 变量存储逻辑值
如:全国 14 亿人每个人是否阳过,就可以用 14 亿个 bit 来存储信息
1 | 设置位的值 |
3. 事务
Redis 事务
事务本质:一组命令的集合
一个事务中的所有命令都会被序列化,在事务执行过程中会按照顺序执行!
特性:一次性、顺序性、排他性
MySQL中的事务:ACID
Redis 单条命令是保证原子性的,但是事务不保证原子性
Redis 事务没有隔离级别的概念,所以不存在类似 MySQL 中的幻读、脏读等情况
所有的命令在事务中并没有直接被执行!只有发起执行命令的时候才会执行
Redis 的事务:
- 开启事务(
multi) - 命令入队(
...) - 执行事务(
exec) - 放弃事务(
discard)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> get k2
QUEUED
127.0.0.1:6379(TX)> set k3 v3
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) OK
3) "v2"
4) OK
1
2
3
4
5
```ad-tip
"编译型异常"(代码语法就有问题,会被直接检查出来):事务中的**所有命令都不会执行**(如命令缺少参数等)
"运行时异常":在执行命令时,有问题的命令会抛出异常,**其他命令会正常执行**(如对字符串执行加1操作等)
Redis 实现乐观锁
悲观锁
- 很悲观,认为什么时候都可能会出现问题,所以无论做什么都会加锁!
- 这样会大大影响程序执行效率
乐观锁
- 很乐观,认为什么时候都不不会出问题,所以不会上锁!
- 更新数据的时候会做出判断,在此期间是否有人修改过数据(在 MySQL 中通过
version字段实现)
监控
在事务开启前,对 key 进行监控(相当于 加锁/
getVersion())如果启动事务后,被监控的 key 被其他线程修改,则事务必定执行失败!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23set money 10
监控 key
watch money
开启事务
multi
incrby money 10
此时其他线程对 money 进行了修改
exec
(nil)
执行失败以后,重新执行需要先放弃监控
unwatch money
watch money
4. Redis 持久化
1 | **工作和面试的重点!** |
Redis 是内存数据库,如果不将内存中的数据库状态保存到磁盘中,一旦服务器进程退出,服务器中的数据库状态也会消失,所以 Redis 提供了持久化功能
RDB(Redis DataBase)
在 RDB 模式下,Redis 会将数据库状态保存在文件:dump.rdb 中,在 Redis 启动时会自动检查 dump.rdb 文件,恢复其中的数据!
1 | # dump.rdb文件位置: |
RDB工作流程: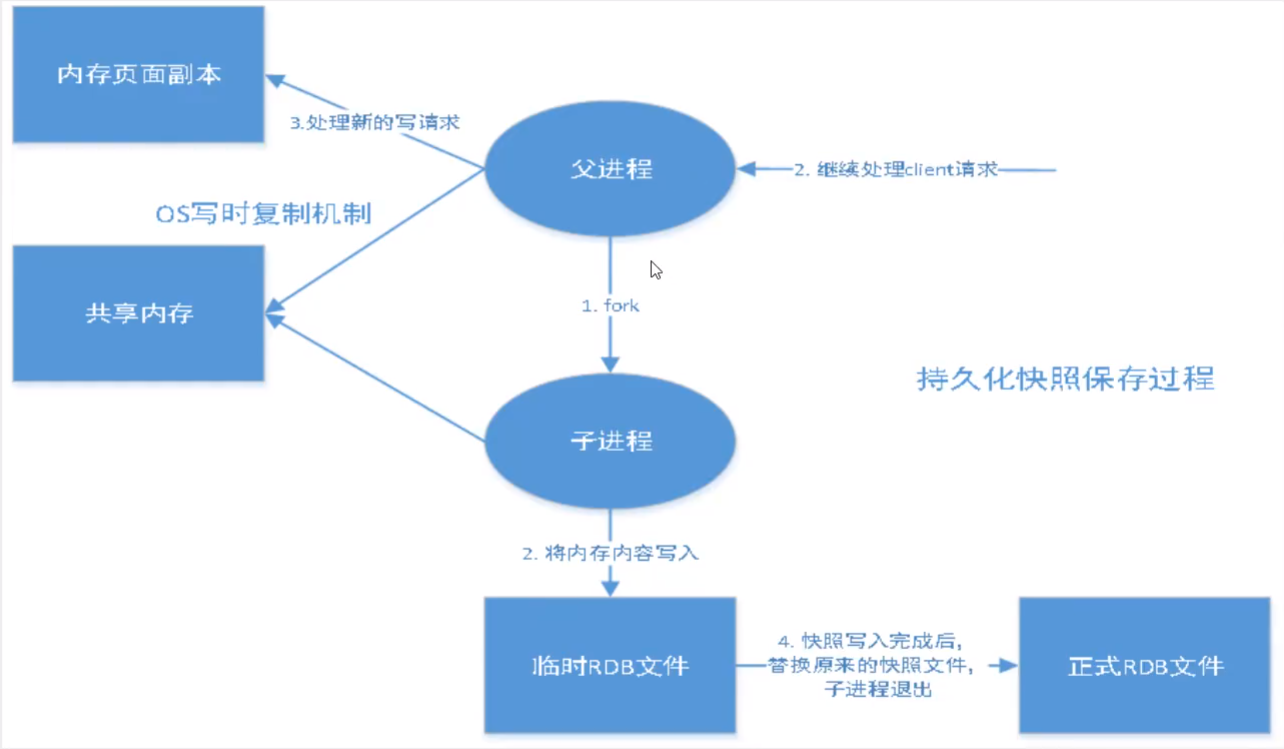
触发生成 dump.rdb 的规则:
满足配置文件中设置的
save规则1
2# 每3600s对key有1次操作就生成一次 dump.rdb,以此类推
save 3600 1 300 100 60 10000执行
flushall命令退出
redis
优点:
1. 适合大规模的数据恢复
2. 如果对数据完整性要求不高时可以使用
缺点:
1. 需要一定的时间间隔进行操作,如果在时间间隔内 redis 宕机,则数据就消失了
2. fork 进程的时候需要占用一定内存空间
AOF(Append Only File)
将所有命令(不包括读操作)以日志的形式记录下来,保存在一个文件中(appendonly.aof),Redis 会在启动之初根据这个日志文件的内容将写指令从前到后执行一次以完成数据恢复工作!
默认是不开启的,只需要将 redis.conf 文件中的 appendonly no 改为 yes ,重启即可生效。
如果 appendonly.aof 有错误,Redis 是启动不起来的,我们可以通过工具 redis-check-aof --fix 来修复文件
AOF 工作流程: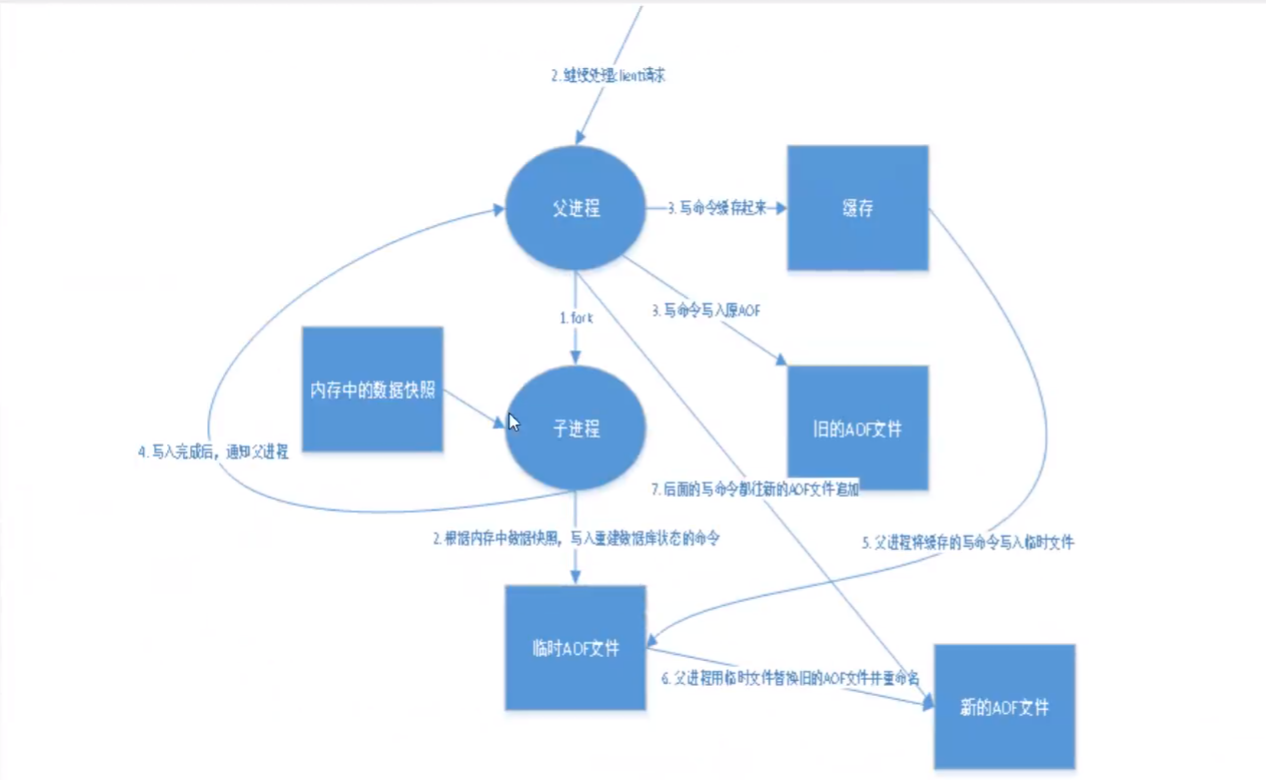
1 | # 三种同步方式 |
三种同步方式各自优点:
1. 每次修改都同步,文件完整性更好
2. 每秒同步一次,可能会丢失 1s 的数据
3. 从不同步,效率最高
缺点:
1. 对于数据文件来说,AOF 远远大于 RDB,修复的速度也比 rdb 慢
2. AOF 运行效率比 RDB 慢
拓展:
1 | collapse: open |
5. Redis 发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接受消息。类似于微博、微信等的关注系统。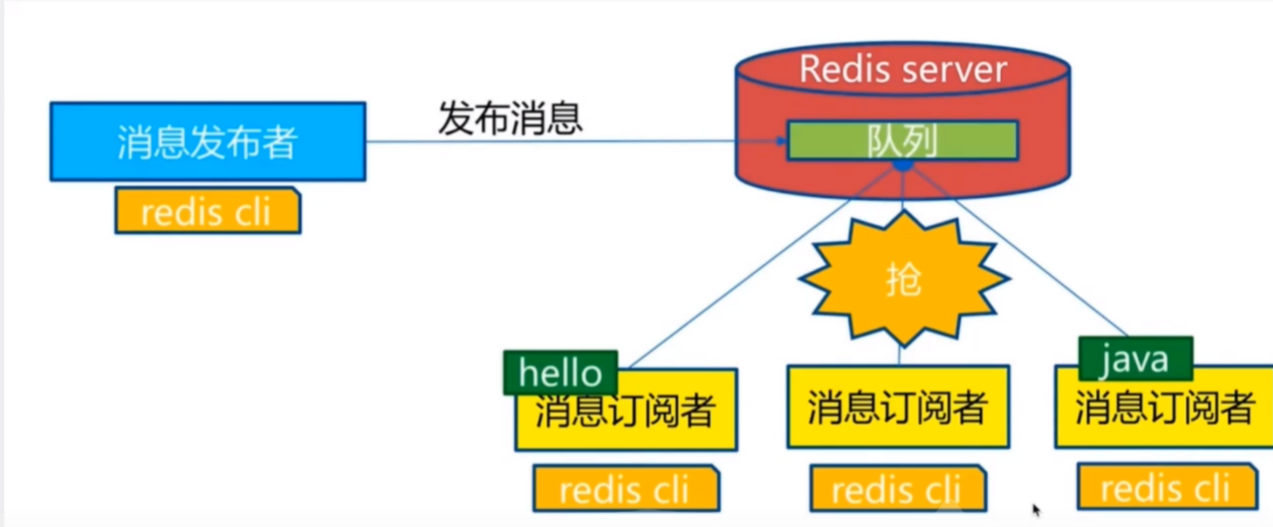
发布订阅命令: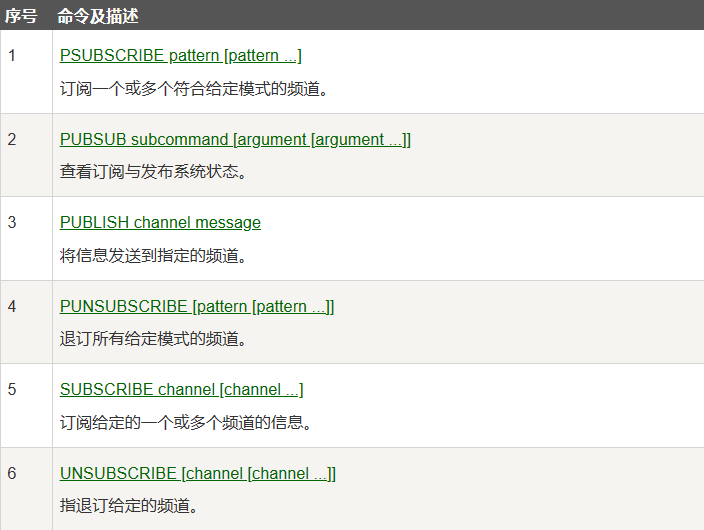
订阅端: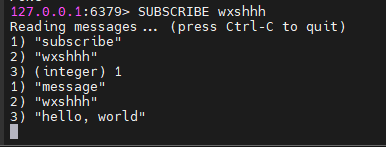
发布端:
使用场景:
- 实时消息系统
- 实时聊天(频道当作聊天室,将信息回显给所有订阅者)
- 订阅、关注系统
1 | 稍微复杂的场景,就会使用一些消息中间件,如 MQ、KAFKA 等 |