【机器学习】异常检测文献阅读:关键算法篇
1 k-NN
2 LOF(Local Outlier Factor)
2.1 Article
| Abbreviation | Paper Title | Venue | Year | Author | Materials |
|---|---|---|---|---|---|
| LOF | LOF: identifying density-based local outliers | ACM SIGMOD Record | 2000 | Markus M. Breunig、Hans-Peter Kriegel、Raymond T. Ng、Jörg Sander |
2.2 Aim
In this paper, we contend that for many scenarios, it is more meaningful to assign to each object a degree of being an outlier. This degree is called the local outlier factor (LOF) of an object.
2.3 Key Notes
Definition 1: (Hawkins-Outlier)
An outlier is an observation that deviates so much from other observations as to arouse suspicion that it was generated by a different mechanism.

Definition 2: (DB(pct, dmin)-Outlier)
An object p in a dataset D is a DB(pct, dmin)-outlier if at least percentage pct of the objects in D lies greater than distance dmin from p, i.e., the cardinality of the set {q ∈ D | d(p, q) ≤ dmin} is less than or equal to (100 − pct)% of the size of D.
Definition 3: (k-distance of an object p, 点 p 距离第k个邻居的距离)
For any positive integer k, the k-distance of object p, denoted ask-distance(p), is defined as the distance d(p,o) between p and an object o ∈ D.
Definition 4: (k-distance neighborhood of an object p, 点 p 的 k 个邻居)
Given the k-distance of p, the k-distance neighborhood of p contains every object whose distance from p is not greater than the k-distance.
Definition 5: (reachability distance of an object p w.r.t. object o)
Definition 6: (local reachability density of an object p)
局部可达密度:p 的第 k 邻域内到点 p 的平均可达距离的倒数
Definition 7: ((local) outlier factor of an object p, 局部异常因子)
点 p 的领域点的局部可达密度与点 p 的局部可达密度的平均比值
- LOF(p) ≈ 1:p 与其邻域点的的密度差不多,他们很有可能在同一类中
- LOF(p) > 1:p 点密度越小于其邻域点的密度,p 点是异常点的可能性越大
- LOF(p) < 1:p 点密度越大于其邻域点的密度,p 点为密集点
Determining a Range of MinPts Values
- The first guideline we provide for picking MinPtsLB is that it should be at least 10 to remove unwanted statistical fluctuations.
- The guideline we provide for picking MinPtsUB is the maximum number of “close by” objects that can potentially be local outliers.
In this paper, we show that for many situations, it is meaningful to consider being an outlier not as a binary property, but as the degree to which the object is isolated from its surrounding neighborhood.





2.4 Background
For many KDD applications, such as detecting criminal activities in E-commerce, finding the rare instances or the outliers, can be more interesting than finding the common patterns. Existing work in outlier detection regards being an outlier as a binary property.
2.5 Key result
Use LOF to judge the outlier-ness of a data in datasets
2.6 Comment
3 iForest(Isolation Forest)
3.1 Article
| Abbreviation | Paper Title | Venue | Year | Author | Materials |
|---|---|---|---|---|---|
| IForest | Isolation forest | ICDM | 2008 | Fei Tony Liu、Kai Ming Ting、Zhi-Hua Zhou | [PDF] |
3.2 Aims
This paper proposes a fundamentally different model-based method that explicitly isolates anomalies instead of profiles normal points.
3.3 Key Notes
3.3.1 rationale
Anomalies are more susceptible to isolation and hence have short path lengths.


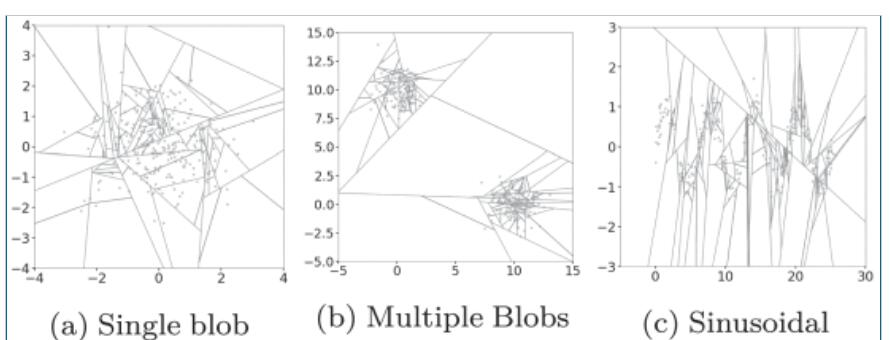
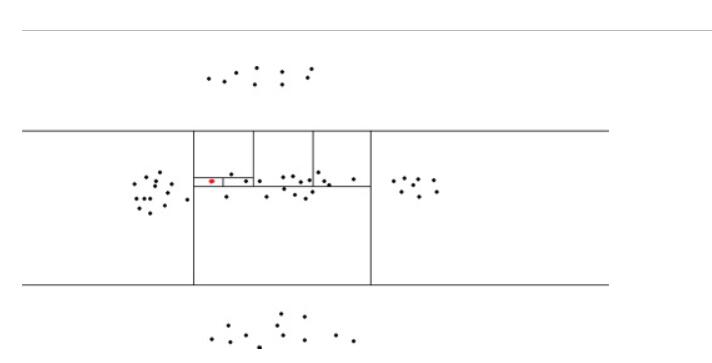
3.3.2 Defifinition : Isolation Tree.
Let T be a node of an isolation tree. T is either an external-node with no child, or an internal-node with one test and exactly two daughter nodes (T_l,T_r). A test consists of an attribute q and a split value p such that the test q < p divides data points into T_l and T_r.
随机选择一个属性 Attr
随机选择该属性的一个值 Value
根据Attr对每条记录进行分类,把Attr小于Value的记录放在左子节点,把大于等于Value的记录放在右子节点
然后递归的构造左子节点和右子节点,直到
1)传入的数据集只有一条记录或者多条一样的记录
2)树的高度达到了限定高度

3.3.3 Defifinition : Path Length h(x).
measured by the number of edges x traverses an iTree from the root node until the traversal is terminated at an external node.
叶子节点到根节点的路径长度

3.3.4 Anomaly score
The maximum possible height of iTree grows in the order of n, the average height grows in the order of log n
Normalization of h(x) by any of the above terms is either not bounded or cannot be directly compared.
对于一个包含n条记录的数据集,其构造的树的高度最小值为 log(n),最大值为 n-1, 直接归一化存在问题,故采用复杂一点的公式进行归一化:

s(x,n) 就是记录 x 在由 n 个样本的训练数据构成的 iTree 的异常指数
- if instances return s very close to 1, then they are definitely anomalies
- if instances have s much smaller than 0.5, then they are quite safe to be regarded as normal instances
- if all the instances return s ≈ 0*.*5, then the entire sample does not really have any distinct anomaly
3.3.5 IForest
随机采样一部分数据去构建每一颗 ITree,并且保证 ITree 之间的差异性

reason of sampling
Large sampling size reduces iForest’s ability to isolate anomalies as normal instances can interfere with the isolation process and therefore reduces its ability to clearly isolate anomalies.

bulid stage
- The first (training) stage builds isolation trees using subsamples of the training set.
- The second (testing) stage passes the test instances through isolation trees to obtain an anomaly score for each instance
height limit:
The rationale of growing trees up to the average tree height is that we are only interested in data points that have shorter-than -verage path lengths, as those points are more likely to be anomalies.
3.4 Background
The concept of isolation has not been explored in the current literature and the use of isolation is shown to be highly effective in detecting anomalies with extremely high effificiency.
Most existing model-based approaches to anomaly detection construct a profile of normal instances, then identify instances that do not conform to the normal profifile as anomalies. Notable examples such as statistical methods, classifification-based methods , and clustering-based methods all use this general approach. Two major drawbacks of this approach are:
(i) the anomaly detector is optimized to profifile normal instances, but not optimized to detect anomalies—as a consequence, the results of anomaly detection might not be as good as expected, causing too many false alarms (having normal instances identifified as anomalies) or too few anomalies being detected;
(ii) many existing methods are constrained to low dimensional data and small data size because of their high computational complexity.
3.5 Key result
iForest performs signifificantly better than a near-linear time complexity distance-based method, ORCA, LOF and RF in terms of AUC and execution time, especially in large data sets. In addition, iForest converges quickly with a small ensemble size, which enables it to detect anomalies with high efficiency.
For high dimensional problems that contain a large number of irrelevant attributes, iForest can achieve high detection performance quickly with an additional attribute selector
Isolation Forest is an accurate and effificient anomaly detector especially for large databases.