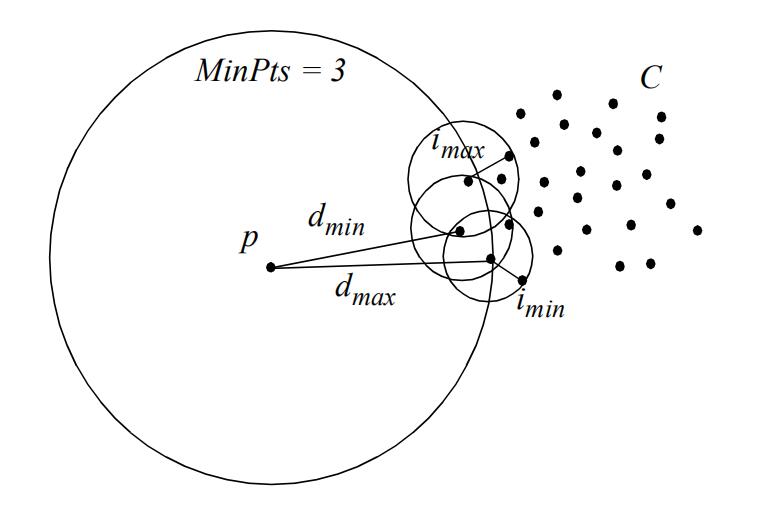
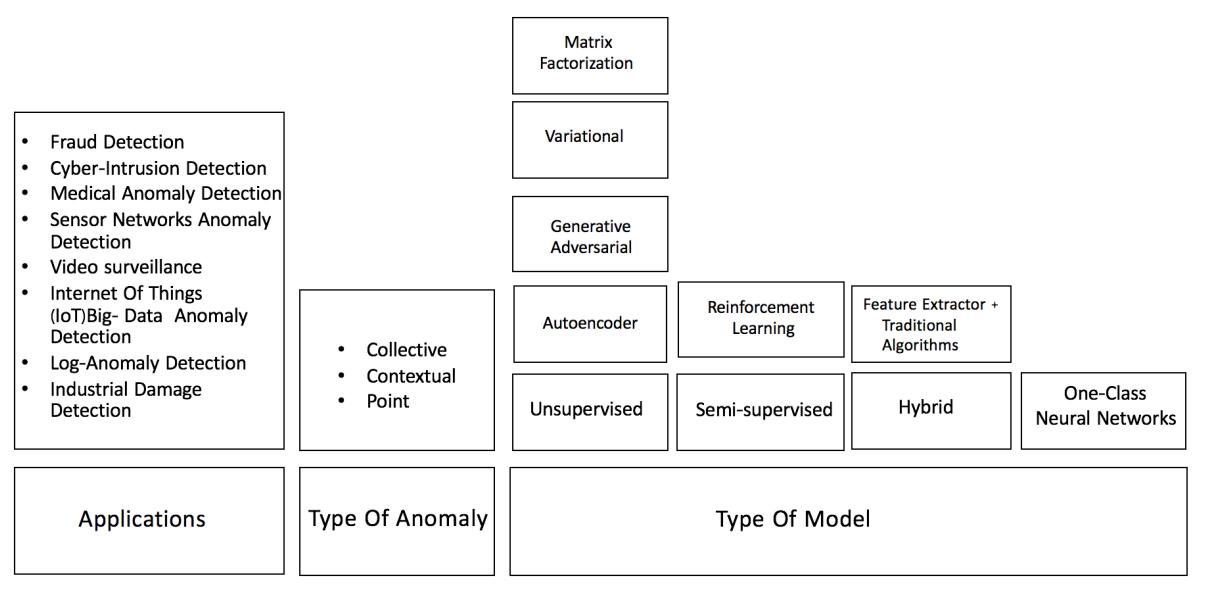
1 深度异常检测分类

|
Assumptions |
Advantages |
Disadvantages |
| Deep learning for feature extraction |
深度学习模型提取的特征保留了有助于区分异常实例与正常实例的具有辨识性的信息 |
1. 可用大量最新和现成的深度学习模型 2. 可以提供强大的降维功能 3. 易于实现 |
1. 特征提取和异常评分脱节 2. 预训练的深度模型仅限于特定类型的数据 |
1.2 Learning feature representations of normality
|
Assumptions |
Advantages |
Disadvantages |
| AE(AutoEncoders) |
正常实例比异常实例更易在被压缩的空间中重建 |
1. 简单易懂,适用于不同的数据类型 2. 可以利用多种不同类型的强大 AE 变体进行异常检测 |
1. 训练数据中的不规则性(infrequent regularities)和异常值本身的存在可能会影响所学习到的特征表示 2. 数据重建的目标函数被设计用来进行数据降维或数据压缩,而不是进行异常检测。 As a result, the resulting representations are a generic summarization of underlying regularities, which are not optimized for detecting irregularities. |
| GAN |
正常实例比潜在的异常实例更好生成 |
1. GAN已经证明可以生成逼真的实例(尤其是图像数据),可以检测出在潜在空间中重建的很差的异常实例 2. 大量现有的基于GAN的模型和理论可以用于异常检测 |
1. GAN的训练会遇到诸多问题,例如无法收敛和模式崩溃(mode collapse),这会导致在训练基于GAN的异常检测模型时会遇到很大的困难 2. 生成网络可能会被误导并生成正常实例之外的数据实例,尤其是当给定数据集的真实分布较为复杂或训练数据包含异常时 3. 基于GAN的异常评分可能不是最佳的,因为建立在生成器网络之上,不是为了异常检测而是为数据生成设计的 |
| Predictability Modeling |
正常实例通常比异常实例更好预测 |
1. 大量序列学习技术(sequence learning techniques)可以被适应并结合到该方法中 2. 可以学习多种不同的时间和空间依赖(temporal and spatial dependencies) |
1. 该方法仅限于序列数据(sequence data)的异常检测 2. 序列预测会花费较多的时间 3. 异常检测的结果并不是最优的,因为他的根本目标是进行序列预测而不是异常检测 |
| Self-supervise Classification |
与异常实例相比,正常实例与自监督分类器的一致性更高 |
1. 在无监督和半监督学习中的表现都很好 2. Anomaly scoring is grounded by some intrinsic properties of gradient magnitude and its updating. |
1. 特征转换操作通常依赖于数据,变换操作仅适用于图像数据 2. 尽管以端到端的方式训练分类模型,但是基于一致性的异常分数是是来源于分类分数而不是优化中的集成模块,因此结果不是最优的 |
| Distance-based Measure |
通常异常实例分布在原离其邻居的地方 |
1. 基于距离的异常检测简单明了,并且在文献中有丰富的理论支持 2. 在低维空间中工作,可以有效地处理无法被传统的基于距离的异常检测算法处理的高维数据 3. 他们能够学习专门为自己量身定做的特征表示 |
1. 涉及到大量的计算 2. 可以受到基于距离的异常检测算法固有弱点的限制 |
| One-class Classification-based Measure(OC) |
所有的正常实例都来自于单个(抽象)实例,可以通过一个紧凑(compact)模型概括,异常不属于该模型 |
1. 在文献中对 OC -based 方法进行了充分的研究并且为 deep OC-based 方法提供了坚实的根基 2. The representation learning 和 OC 分类模型可以被统一起来,去学习量身定做和更加优化的特征表示 3. 免于用户自己手动选择合适的内核功能(kernel functions) |
1. 在正常实例中具有复杂分布的数据集可能使模型失效 2. The detection performance is dependent on the one-class classification-based anomaly measures |
| Clustering-based Measure |
正常实例比异常实例对集群具有更高的依从性(adherence) |
1. 有许深度聚类方法和理论可以用来支持异常检测 2. 与传统的基于聚类的方法相比,基于深度聚类的方法会学习专门优化特征,这些形式比原始数据更易发现异常,特别是在处理复杂数据时 |
1. 异常检测的结果严重依赖于聚类的结果 2. 聚类过程中可能会因为训练数据出现污染而产生偏差 |
1.3 End-to-end Anomaly Score Learning
|
Assumptions |
Advantages |
Disadvantages |
| Ranking Models |
There exists an observable ordinal variable that captures some data abnormality. |
1. 可以使用调整后的损失函数直接优化异常分数 2. They are generally free from the definitions of anomalies by imposing a weak assumption of the ordinal order between anomaly and normal instances 3. 这种方法可以建立在诸如学习排名等领域的成熟排名技术的理论基础之上 |
1. 需要某种形式的标记过的异常 2. 由于模型专门用于检测少数标记过的异常,因此可能无法推广到一些与标记异常有不同特征的未被发现的异常上 |
| Prior-driven Model |
The imposed prior captures the underlying (ab)normality of the dataset |
1. 可以在给定先验(given prior)条件下直接优化异常分数 2. 提供了一个灵活的框架,可以将不同的优先级分布合并到异常分数学习中 3. 先验(the prior)也可以得到比其他方法更具解释性的异常分数 |
1. 很难设计一个普遍适用于不同异常检测应用场景的先验 2. 不能很好地适应基础分布则模型的工作效率较低 |
| Softmax Likelihood Models |
得到正常实例是高概率时间而得到异常实例是低概率事件 |
可以将不同类型的交互方式合并到异常分数学习过程中 |
1. 交互的计算可能非常昂贵 2. 异常分数学习在很大程度上取决于反面样本(negative samples)生成的质量 |
| End-to-end One-class Classification |
1. 近似异常的实例可以被有效的合成 2. 所有的正常实例都可以被一个单分类模型概况 |
1. 异常分类模型被以端到端的方式对抗式的优化 2. 有丰富的理论支持 |
1. 难以保证所生成的参考实例与未知异常十分相似 2. GAN 的不稳定性会导致异常分类性能不稳定 3. 仅限于半监督异常检测场景 |
参考自 Deep Learning for Anomaly Detection: A Review
2 深度异常检测模型基础
| 模型 |
描述 |
类型 |
| AE(AutoEncoder) |
AE 重构输入数据来表示多个隐藏层中的数据,从而有效学习身份函数(identity function)。当在正常数据中训练 AE 时,AE 无法重构异常数据样本,因此会产生较大的重构误差(reconstruction error),产生高残留误差的样本数据被认为是异常值。 |
Semi-supervised,Un-supervised |
| RBM(Restricted Boltzmann Machine) |
一种可通过输入数据集学习概率分布的随机生成神经网络 |
Semi-supervised |
| DBN(Deep Belief Networks) |
使用 DBN 进行异常检测的假设是,RBM 被用作带有反向传播算法的定向编码-解码网络。 |
Semi-supervised |
| AAE(Adversarial AutoEncoder) |
我们都知道AE需要把一个真实分布映射成隐层的 z,AAE 在此加上对抗思想来优化这个 z |
Semi-supervised ,Un-supervised |
| CNN-Relief,CNN-SVM |
|
Semi-supervised |
| CNN |
CNN 能够从具有复杂结构的高维数据中提取复杂的隐藏特征,使其能够在序列和图像检测中用作特征提取器。 |
Semi-supervised |
| RNN |
RNN可以获得时序数据的特征,但是随着时间步长的增加,获取时序数据的特征也会越来越困难。 |
Semi-supervised ,Un-supervised |
| GAN |
学习精确的数据分布以便生成具有变化的新数据点。 |
Semi-supervised ,Un-supervised |
| CorGAN(Corrupted GAN) |
|
Semi-supervised |
| AE-OCSVM,AE-SVM |
|
Hybrid |
| DBN-SVDD,AE-SVDD(Support Vector Data Description) |
|
Hybrid |
| DNN-SVM |
|
Hybrid |
| DAE-KNN,DBN-Random Forest,CNN-Relief,CNN-SVM |
|
Hybrid |
| AE-CNN,AE-DBN |
|
Hybrid |
| AE-KNN |
|
Hybrid |
| CNN-LSTM-SVM |
|
Hybrid |
| RNN-CSI |
|
Hybrid |
| CAE-OCSVM |
|
Hybrid |
| LSTM(Long Short Term Memory Networks) |
是 RNN 的一种特殊类型,可以存储先前时间步长信息 |
Un-supervised |
| STN(Spatial Transformer Networks) |
STN 包含结合了 CNN 和 LSTM 的深层神经网络体系结构用以提取时空特征。时间特征(通过LSTM在近时间点之间的建模相关性)和空间特征(通过 CNN 的局部空间相关性建模)可以有效的检测异常值。 |
Un-supervised |
参考自 Deep learning for anomaly detection: A survey